企业与个人网络营销一站式服务商
网站建设 / SEO优化排名 / 小程序开发 / OA
0731-88571521
136-3748-2004
首页
斌网
斌网网络
发展历程
我们的优势
联系我们
服务
网站建设
网站优化推广
网站运维
小程序开发
资讯
新闻中心
网站建设
做小程序开发
SEO优化推广
精辟网文
网络营销
客户与伙伴
法律法规
维护与安全
案例
产品厂家
商务服务
单位集团
小程序案例
联系
新闻中心
网站建设
做小程序开发
SEO优化推广
精辟网文
网络营销
客户与伙伴
法律法规
维护与安全
google与百度是怎样识别文章是不是伪原创
信息来源:
长沙网站建设
发布时间:2011-4-5 浏览:
第一点、关于哪些词是蜘蛛不喜欢的呢?那么我们来看一下:总的来讲搜索引擎会过滤“的,了,呢,啊”之类的重复率非常之高的词,有人会问是为什么呢?很简单,因为这类词是对排名无帮助的无用词语。
第二点、在谈到这里要谈伪原创百度与谷歌是怎么算法,和判定的?为什么有时候转换近义词无效。那么从这里开始就算是小戴个人的一点经验总结了。我们都知道目前在网络然市场上有一堆伪原创工具能够将词语伪原创比如将“电脑”伪原创为“计算机”等这样的近义词,那么有什么理由不相信强大的搜索引擎不会伪原创?所以肯定的,搜索引擎一定会近义词伪原创,当搜索引擎遇到“电脑”和“计算机”时,会将他们自动转换这里姑且假设为A,所以很多情况下的近义词伪原创不收录的原因就在这里。
第三点、重点谈一下为什么有时候不仅近义词转换了并且连打乱句子与段落依然无效果呢。当搜索引擎过滤掉无用词,并将各类近义词转化为A,B,C,D后开始提取出这个页面最关键的几个词语A,C,E如果大家不太明白,那么(这里举个例子,实际可能提取的关键字不是ACE三个而是1个到几十个都是说不定的)。并且将这些词进行指纹记录。这样也就是说,近义词转换过的并且段落打乱过的文章和原文对于搜索引擎来说是会认为一模一样的。如果你们不明白,那就好好的琢磨一下,小戴的语言功底不太好,希望大家能够理解。
第四点、这段更深层次解释为什么几篇文章段落重组的文章依然可能会被搜索引擎识别出。大家会可能觉得奇怪了?首先既然百度能够生成指纹自然也能解码指纹,段落重组的文章不过是重要关键字的增加或者减少,这样比如有两篇文章第一篇重要关键字是ABC,而第二篇是AB,那么搜索引擎就可能利用自己一个内部相似识别的算法,如果相差的百分数在某个值以下就放出文章并且给予权重,如果相差的百分数高于某个值那么就会判断为重复文章从而不放出快照,也不给予权重。这也就是为什么几篇文章段落重组的文章依然可能会被搜索引擎识别出的原因。
第五点、我要解释下为什么有些伪原创文章仍然可以被收录的很好。我上面的推理只是对于百度识别伪原创算法的大致框架,实际上谷歌百度对于识别伪原创的工作要更加庞大并且复杂的多,谷歌一年就会改变两百次算法足以看出算法的复杂性。为什么某些伪原创的文章依然可以被收录的很好。只有两个原因:
上一条:
网站建设中 身份还是职业 对于互联网站长的一点思考
下一条:
提升网站权重从快照及内容收录中看问题
案例鉴赏
多年的网站建设经验,斌网网络不断提升技术设计服务水平,迎合搜索引擎优化规则
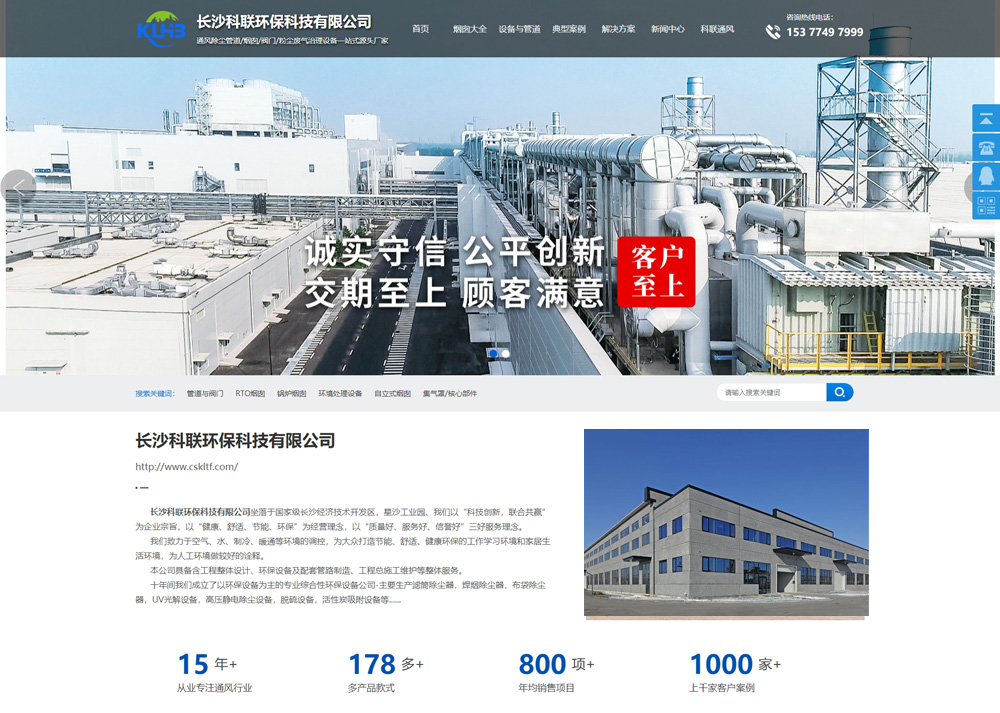
长沙科联环保科技有限公司
长沙科联环保科技有限公司坐落于国家级长沙经济技术开发区,星沙工业园、我们以“科技创新,联合共赢”为企业宗旨,以“...
TIME: 2022/11/13 19:46:14
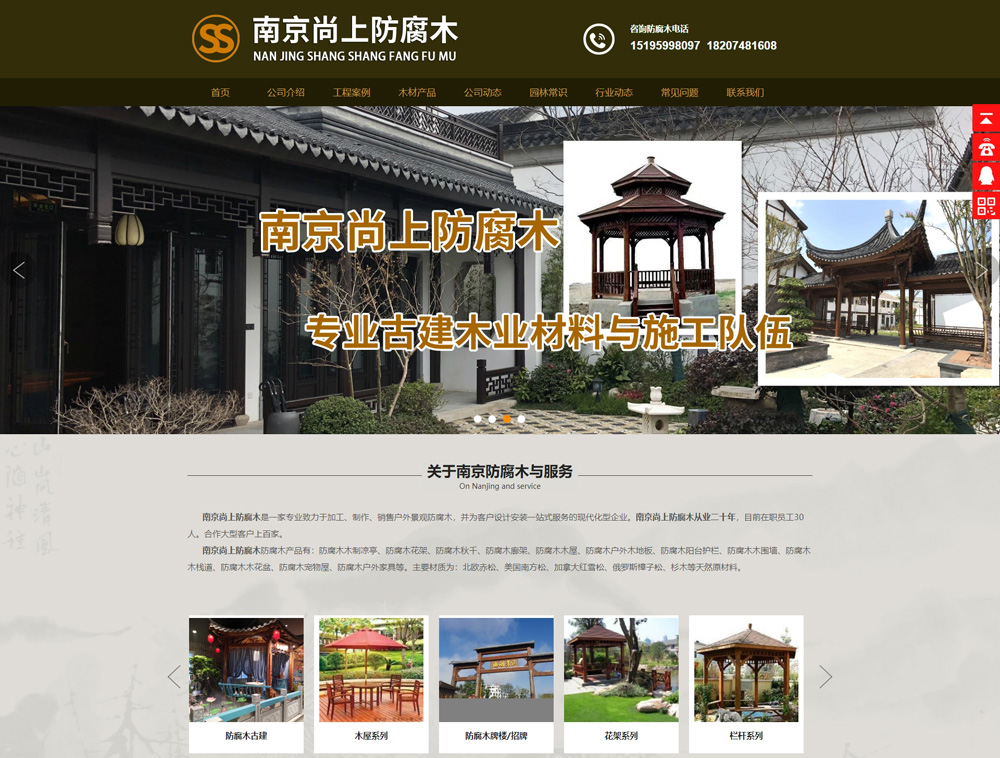
南京尚上防腐木
南京尚上防腐木是一家专业致力于加工、制作、销售户外景观防腐木,并为客户设计安装一站式服务的现代化型企业。南京尚上...
TIME: 2022/11/13 19:38:10
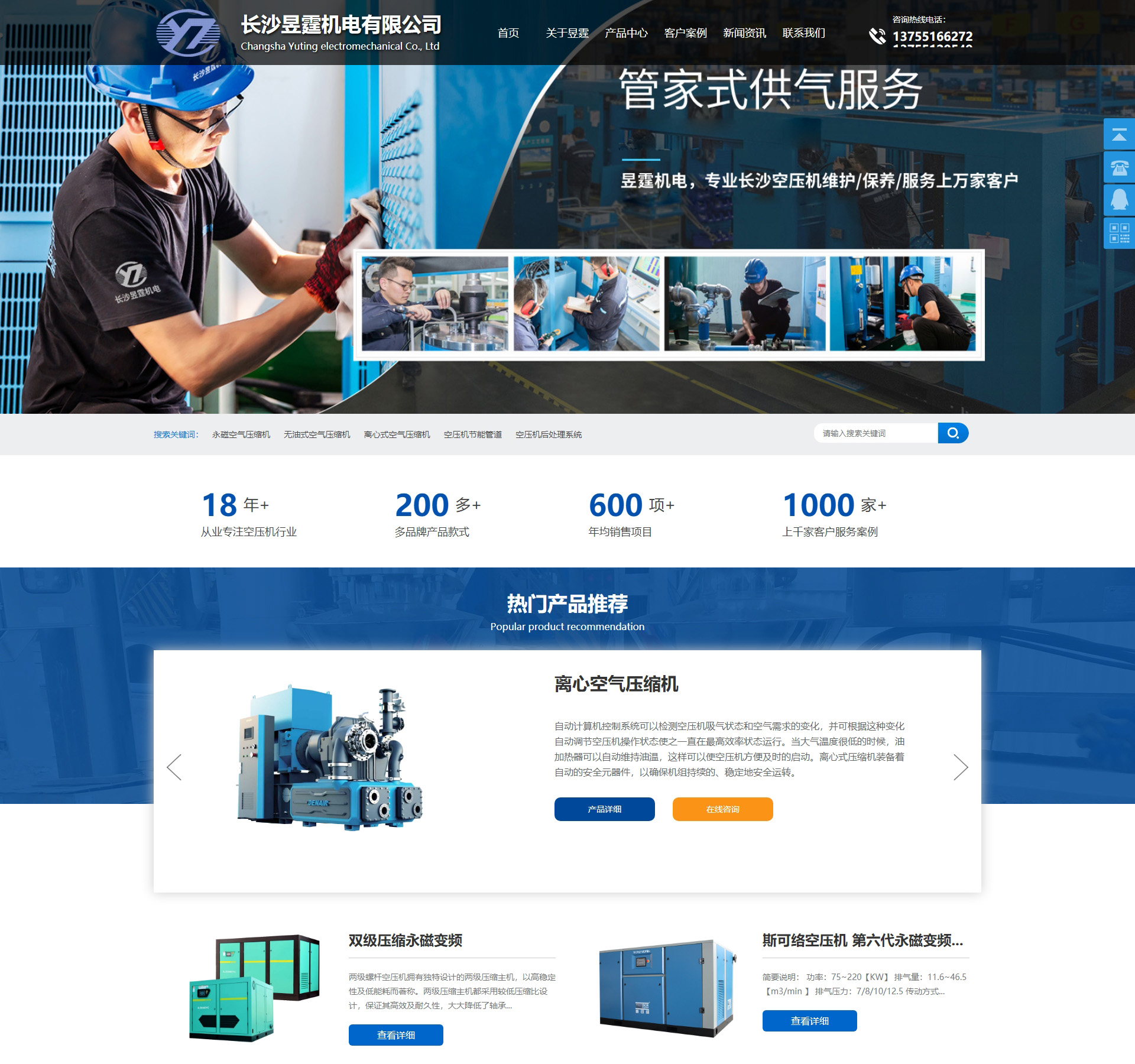
长沙昱霆机电有限公司
长沙昱霆机电有限公司是长沙空压机_长沙空压机保养_湖南空压机维修_长沙空压机机头维修-长沙昱霆机电有限公司从业十...
TIME: 2022/11/13 19:30:14
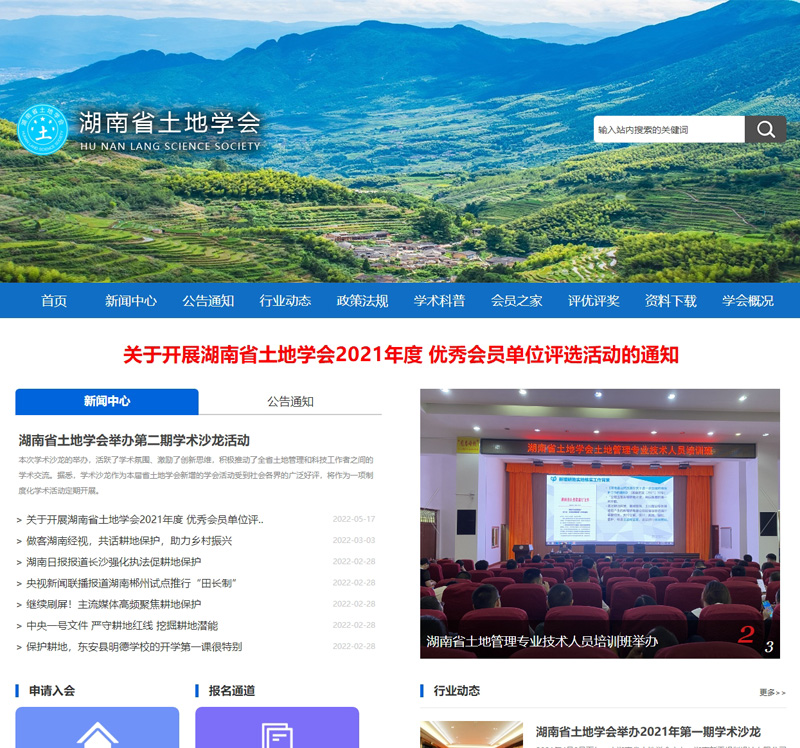
湖南省土地学会,湖南土地学会,湖南土...
湖南省土地学会是全省土地科技工作者自愿组成,并依法登记的学术性、非盈利性、公益性的法人社会团体,接受湖南省科学技...
TIME: 2022/6/16 0:04:16
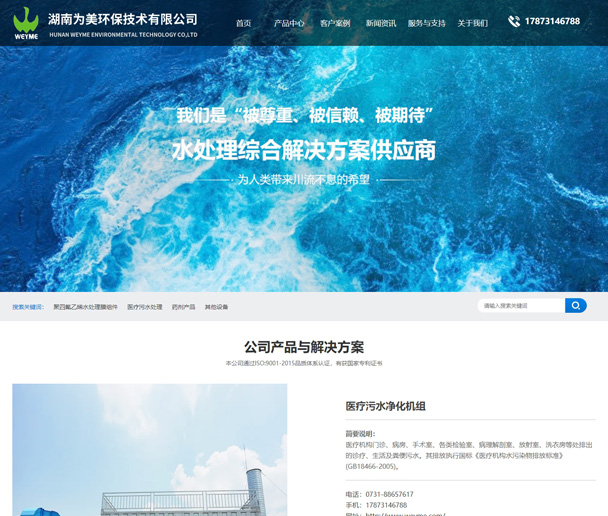
湖南为美环保技术有限公司,医疗污水净...
湖南为美环保技术有限公司应“绿水青山就是金山银山”之势而生,秉持“为民环保,美丽干净”理想信念,坚守新时代锦绣环...
TIME: 2022/6/6 0:10:41
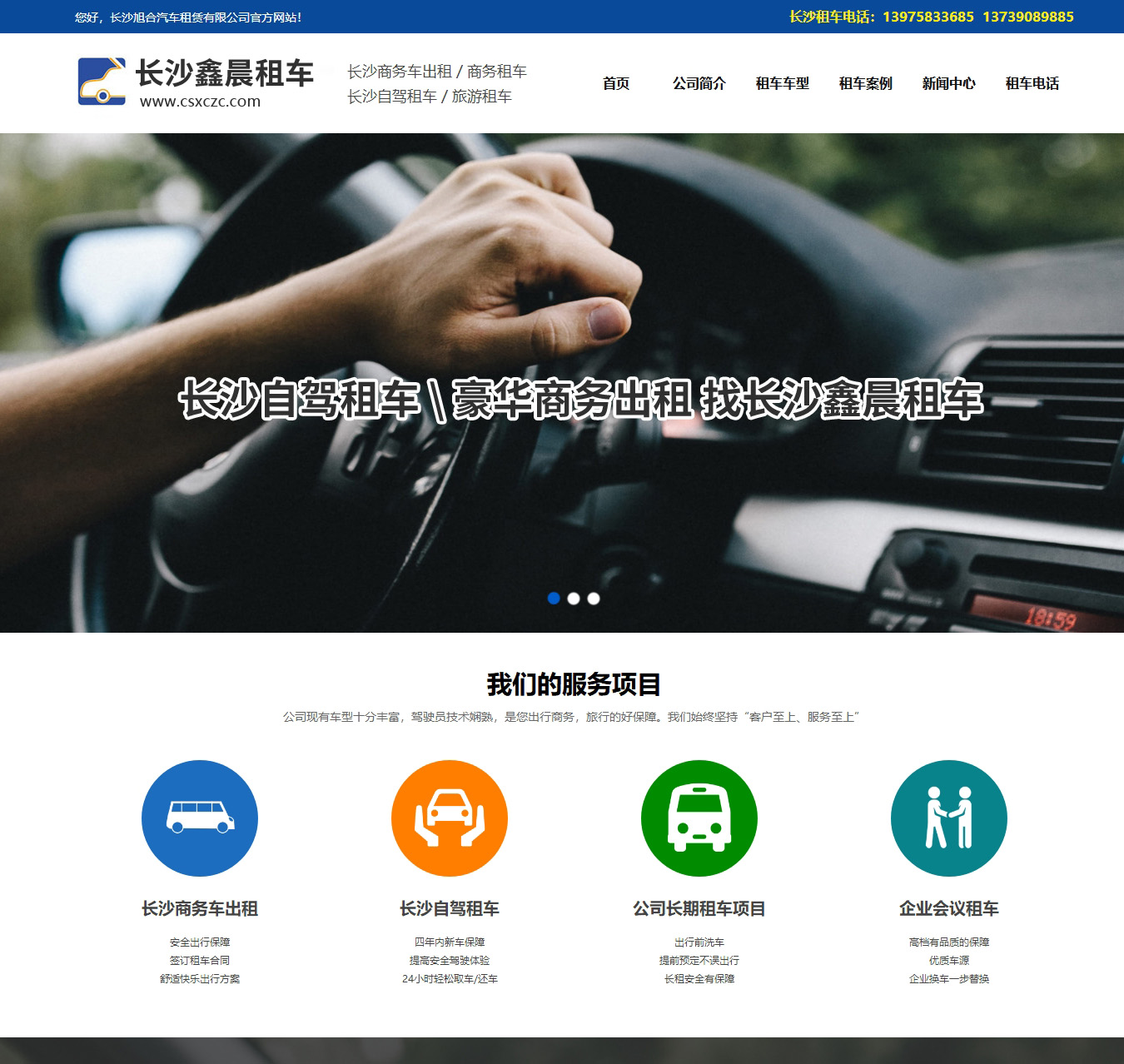
长沙租车公司-长沙鑫晨租车
长沙鑫晨租车(长沙租车网)于2008年,已精工细作多年。现以成为长沙地区较早的租车公司之一。公司现有车型十分丰富...
TIME: 2022/6/6 0:10:13
新闻中心
多年的网站建设经验,网至普不断提升技术设计服务水平,迎合搜索引擎优化规则
成功签定 湖南GJ生物科技有限公司 网站建设优化合同
富晒米就是通过在在种植稻米时候的补硒,从而生长出富含硒的大米。富硒大米属于功能性农产品,是富含硒...
TIME: 2023/9/1 18:20:20
成功签定 长沙TX光电科技有限公司 网站建设合同
监控系统的维护;乐器零售;信息系统集成服务;电气设备系统集成;信息电子技术服务;电子产品设计服务...
TIME: 2023/5/6 11:31:52
成功签定 长沙市YS机械工程有限公司 网站升级与公司地图标注合同
公司及外资企业建立的长期的良好合作关系(比亚迪、思达仪表、东光电子、东亚科技、富士康等)。从客户...
TIME: 2023/5/4 21:25:24
成功签定 湖南NF住宅工业有限公司 网站设计合同
湖南NF住宅工业有限公司经过近10年的专业木别墅设计、加工、建造,成为中国木别墅行业的领军者。公...
TIME: 2023/4/22 21:24:18
成功签定 东莞市HY电子有限公司 外贸网站设计合同
电子元器件与机电组件设备销售;显示器件销售;显示器件制造;五金产品制造;五金产品零售;五金产品研...
TIME: 2023/4/16 21:19:28
成功签定 湖南JY智能装备有限公司 网站升级改版合同
湖南JY智能装备有限公司主要生产经营抛丸清理设备、涂装设备、除尘设备及非标设备的维修改造服务,包...
TIME: 2023/4/6 21:24:01
成功签定 湖南H杰机械设备有限公司 网站优化排名合同
湖南H杰机械设备有限公司立足于自主研发具有独特性能产品,主导产品覆盖建筑破碎、矿山破碎、工业制粉...
TIME: 2023/3/29 18:37:50
成功签约 湖南DK银行账务处理中心 网站设计合同
所以企业在经营过程中所发生的一切货币收支业务都必须通过企业银行存款账户进行转账结算。而企业为了逃...
TIME: 2023/3/12 10:38:33
成功签约 湖南GY钢膜结构工程有限公司 网站改版升级与网络优化排名合同
湖南GY钢膜结构工程有限公司公司拥有机械加工、金属结构、轻钢结构制作安装全套设备。公司在多年的钢...
TIME: 2023/3/1 16:58:55
成功签定 深圳HX门业有限公司 网站建设与网络优化排名合同
专业代理国际品牌自动感应门、自动平开门、旋转门、圆弧门、气密门及地弹簧、玻璃门夹、闭门器、门禁等...
TIME: 2023/2/24 18:23:48
成功签定 岳阳市平江县YF云母新材料有限公司 网站升级改版合同
主要生产云母纸、云母板、云母带、云母卷、云母管、云母发热膜等产品。是一家集研发、制造和销售于一体...
TIME: 2023/2/24 18:09:23
成功签定 广西黑白根线条,黑白根电梯门套,黑白根石线电梯门套,黑白根线条 网站建设和优化排名合同
广西灌阳石线工艺工厂座落于“大理石黑白根之乡”―- 桂林文市镇!中国较大的大理岩、石灰岩盛产地之...
TIME: 2023/2/16 21:18:17
成功签定 湖南MT电气有限公司 网站保姆托管合同
湖南MT电气有限公司以经济、高效、可靠、智能为设计理念,以用户的需求和期望为目标,帮助用户实现更...
TIME: 2023/2/16 21:14:34
成功签定 湖南S容科技有限公司 网站建设合同
公司的主要业务为研究院所、大学、工厂、国家设立的检测机构和工业领域的科学研究提供世界上先进的仪器...
TIME: 2023/2/16 21:13:35
成功签定 广州WF斯信息技术有限公司 网站建设合同
致力于市场研究调研服务,多年积累并专注品牌、市场、渠道、产品、行业等多个研究领域;覆盖定量、定性...
TIME: 2023/2/16 20:57:31
成功签定 湖南长沙债务调解中心 网站建设与站群优化合同
公司开办以来,已成功操办无数起经济案件,为客户挽回数以亿计的坏帐、赖债、死帐,深受客户的一致辞好...
TIME: 2023/2/14 21:08:45
成功签定 广东CZ市场咨询股份有限公司 网站优化排名合同
广东CZ市场咨询股份有限公司是中国大陆较具竞争力的跨行业市场研究咨询公司之一,总部位于广州,旗下...
TIME: 2023/2/7 10:51:28
成功签定 湖南QY管理咨询有限公司 网站升级改版合同
我们致力于中国科技服务。为中国科学技术事业的快速发展做出贡献,为提高中国企业特别是科技型企业的竞...
TIME: 2023/2/7 10:16:43
友情链接
/ 同行链接QQ:522392221
长沙私人做网站
长沙做网站
深圳网站建设
株洲做网站
东莞做网站
南京防腐木
湖南大拇指养猪设备
株洲做网站
斌网
斌网网络
发展历程
我们的优势
联系我们
服务
网站建设
网站优化推广
网站运维
小程序开发
资讯
新闻中心
网站建设
做小程序开发
SEO优化推广
精辟网文
网络营销
案例
产品厂家
商务服务
单位集团
小程序案例
联系地址
湖南省长沙市天心区韶山南路248号南园503室(潇湘晨报旁)
联系电话
0731-88571521 13637482004
官方网址
WWW.BINWEB.CN WWW.PK0731.COM
WWW.60OA.COM
版权所有 © 长沙市天心区斌网网络技术服务部
湘公网安备 43010302000270号
统一社会信用代码:92430103MA4LAMB24R
网站ICP备案号:湘ICP备13006070号-2
返回顶部
0731-88571521
在线QQ
扫一扫进手机端